| KICKS |
A transaction processing system for CMS & TSO |
The 251 project – Resource Definition ( II )
Page/Swap, VTAM buffers, and Common storage
This is a series of KooKbooK recipes detailing my successful effort to demonstrate over 250 KICKS users sharing VSAM files in the MVS Turnkey under Hercules, with sub-second response time.
The last recipe focused was on the system configuration changes that we knew would be needed. This recipe continues the emphasis on resource definition, now focused on the changes that are necessary as a result of those earlier changes. Adding lots of terminals means VTAM will need more buffers in its buffer pools, and adding more users means more page and swap space will be needed. Furthermore, these changes both result in more CSA usage and that means another parmlib change.
From the VTAM manual (GC28-0688, OS/VS2 SYSTEMS PROGRAMMING LIBRARY: VTAM), available at prycroft6, Chapter 9. Tuning VTAM
“VTAM has 11 storage pools to control the buffering of data. VTAM dynamically allocates and deallocates space in these storage pools for the VTAM control blocks, I/O buffers, and channel programs that control the transmission of this data. …
VTAM and OS/VS2 system performance can be affected by the VTAM storage pool sizes. Pools that are too large can increase fixed storage requirements and can therefore affect paging activity. Pools that are too small can prevent VTAM from starting or can affect VTAM response time (queuing requests for pool elements can cause delays).
A procedure for tailoring the VTAM storage pool values is to (1) initially operate VTAM using the IBM or user-calculated storage pool values, (2) active VTAM storage pool trace facility, and (3) adjust the storage pool values as indicted by the trace data. To do this, consider:
Calculating storage pool values
Tuning storage pool values
Fixing storage pools
To tailor the VTAM storage pools, determine the following values for each VTAM storage pool:
BNO: indicates the maximum number of elements in a pool
BSZ: indicates the size of each element (in bytes) in a pool
BTH: indicates the threshold number of elements for a pool
F: indicates that a pageable storage pool is fixed in storage"
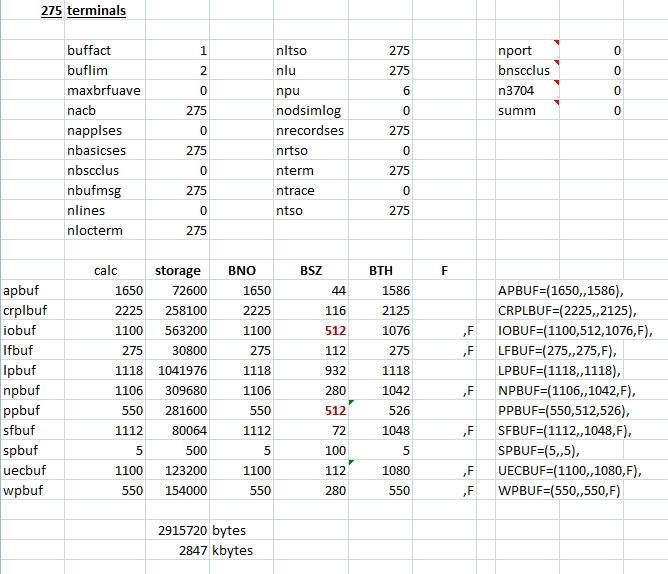
We’re shooting for a network with hundreds of terminals, so using either the IBM default storage pool values (below left), or the TK3UPD supplied pool values (below right) doesn't seem seem like a good idea.
Storage Pool Name
BNO
BSZ
BTH
APBUF
129
44
116
CRPLBUF
208
116
193
IOBUF
100
64
81
LFBUF
104
112
104
LPBUF
64
932
64
NPBUF
192
280
176
PPBUF
175
64
157
SFBUF
163
72
163
SPBUF
3
100
3
UECBUF
34
112
30
WPBUF
78
280
78
Storage Pool Name
BNO
BSZ
BTH
APBUF
128
64
CRPLBUF
256
44
IOBUF
20
3992
10
LFBUF
16
16
LPBUF
32
32
NPBUF
32
8
PPBUF
20
3992
10
SFBUF
32
32
SPBUF
32
32
UECBUF
32
16
WPBUF
64
64
Instead we’ll use the formula in the VTAM manual, figure 9-4, to build a spreadsheet and calculate our own pool values for 275 terminals.
You can click the above table to download the spreadsheet, then cut/paste the pool definitions (APBUF= thru WPBUF=) from the right bottom of the spreadsheet into the bottom of SYS1.VTAMLST(ATCSTR00). While you’re at it, change MAXSUBA to 31. Or just run the following job…
//VTAMLST3 JOB CLASS=A,MSGLEVEL=(1,1),MSGCLASS=A//*//STORE EXEC PGM=IEBUPDTE,REGION=1024K,PARM=NEW//SYSUT2 DD DSN=SYS1.VTAMLST,DISP=SHR//SYSPRINT DD SYSOUT=*//SYSIN DD *./ ADD NAME=ATCSTR00,LIST=ALLCONFIG=00, /* CONFIG LIST SUFFIX */+SSCPID=01, /* THIS VTAMS ID IN NETWORK */+NETSOL=YES, /* NETWORK SOLICITOR OPTION */+MAXSUBA=31, /* MAXIMUM SUBAREAS IN NETWORK */+NOPROMPT, /* OPERATOR PROMPT OPTION */+SUPP=NOSUP, /* MESSAGE SUPPRESSION OPTION */+COLD, /* RESTART OPTION - COLD/WARM */+APBUF=(1650,,1586), /* ACE STORAGE POOL */+CRPLBUF=(2225,,2125), /* RPL COPY POOL */+IOBUF=(1100,512,1076,F), /* FIXED IO */+LFBUF=(275,,275,F), /* LARGE FIXED BUFFER POOL */+LPBUF=(1118,,1118), /* LARGE PAGEBLE BUFFER POOL */+NPBUF=(1106,,1042,F), /* NON WS FMCB */+PPBUF=(550,512,526), /* PAGEBLE IO */+SFBUF=(1112,,1048,F), /* SMALL FIXED BUFFER POOL */+SPBUF=(5,,5), /* SMALL PGBL BUFFER POOL */+UECBUF=(1100,,1080,F), /* USER EXIT CB */+WPBUF=(550,,550,F) /* MESSAGE CONTROL BUFFER POOL */./ ENDUP/*//* ATCSTR00 doesn’t live in SYS1.VTAMOBJ…//
VTAM won’t be able to obtain these buffers (meaning it won’t come up, which also prevents TSO from coming up) until CSA is expanded to fit them. But while we’re making changes to SYS1.VTAMLST let’s also transition away from TK3UPD’s LCLMAJ00 & LCLMAJRP major nodes to the LCL0C0 node we defined in the previous recipe. The LCL0C0 node defines all the resources in those older nodes (except CUU1C7, a 3284, but that 3284 isn’t defined in TK3UPD.CONF, nor in the JRP default configuration). You can use rpf to edit SYS1.VTAMLST(ATCCON00), removing LCLMAJ00 & LCLMAJRP, then adding LCL0C0. Or just run the following job…
//VTAMLST4 JOB CLASS=A,MSGLEVEL=(1,1),MSGCLASS=A//*//STORE EXEC PGM=IEBUPDTE,REGION=1024K,PARM=NEW//SYSUT2 DD DSN=SYS1.VTAMLST,DISP=SHR//SYSPRINT DD SYSOUT=*//SYSIN DD *./ ADD NAME=ATCCON00,LIST=ALL************************************************************************ STARTLIST T U R N K E Y 4 ************************************************************************APPLJRP, /* JES Remote Printing */XAPPLPIES, /* Watchdod application node */XAPPLPIAD, /* PIES standalone admin */XAPPLTSO, /* TSO Application major node */XAPPLTEST, /* VTAM TEST APPLICATION */XLCL0C0 /* LOCAL Non-SNA major node NETSOL*/./ ENDUP/*//* ATCCON00 doesn’t live in SYS1.VTAMOBJ…//
Adding lots of VTAM buffers will require the CSA be enlarged to accommodate. You’ll notice at the bottom of the spreadsheet the storage for the buffer pools is calculated at just under 3 megs, so you should add that to CSA= in SYS1.PARMLIB(IEASYS00). Change CSA=2048 to CSA=5120. Seems like a lot and you’re probably thinking some storage was already allocated to VTAM buffers, and of course you are right. But VTAM isn’t the only thing gobbling up CSA, so let’s start with 5120. We will eventually find it’s just enough…
When you IPL you may notice a new IEA913I message about the size of the private area being less than 8 megs. This is due to our fairly massive increase to CSA space. It's not a problem, you can ignore the message.
We are shooting for over 250 tso users logged on, each with a working set of a couple hundred K (that’s 50-100 megabytes total), so you might guess the page/swap space on the turnkey system (sized for 2-3 users) would be inadequate. You could use the “Interactive Monitor” included on the TK3UPD system to check it. Logon to TSO, then, at the READY prompt, type “IM P”. You’ll see a display that shows the active page and swap space and how much is in use. BTW, If you haven’t used it before it’s well worth the time to learn about the “Interactive Monitor”. Besides the “P” command that displays the page data set info we will also be interested in the “V” command that allows us to check on CSA usage…
To ensure there is enough space we need to add a page pack and a swap pack. Steps I used to do this are:
1. In the tk3upd configuration file CONF/TK3UPD.CONF, after the line
0140 3350 dasd/work00.140 ro sf=shadow/work00_1.140
add the two lines
0141 3350 dasd/page04.141
0142 3350 dasd/swap02.142
2. Create DASD/PAGE04.141 and DASD/SWAP02.142 by copying DASD/WORK00.140
3. IPL the TK3UPD system
a. During the ipl reply “r 00,141” to the first IEA212A message
b. Reply “r 00,142” to the second IEA212 message
c. When the IPL is finished, type
“v 141,online”
“s clip,cua=141,volid=page04”
and then reply “u” to the alter volume message.
d. Then type
“v 142,online”
“s clip,cua=142,volid=swap02”
and then reply “u” to the alter volume message.
e. Add to the end of SYS1.PARMLIB(VATLST00)
“PAGE04,1,2,3350 N” and
“SWAP02,1,2,3350 N”
f. Run the following job, replying (twice) with the master catalog password “secret”
//NEWPAGE JOB CLASS=A,MSGCLASS=A,MSGLEVEL=(1,1),REGION=1024K//PAGESWAP EXEC PGM=IDCAMS//SYSPRINT DD SYSOUT=*//PAGE04 DD DISP=OLD,UNIT=3350,VOL=SER=PAGE04//SWAP02 DD DISP=OLD,UNIT=3350,VOL=SER=SWAP02//SYSIN DD *DEFINE PAGESPACE (NAME(SYS1.PAGEL04) -CYLINDERS(550) -FILE(PAGE04) VOLUME(PAGE04) -UNIQUE)DEFINE PAGESPACE (NAME(SYS1.PAGES02) -CYLINDERS(550) -FILE(SWAP02) VOLUME(SWAP02) -UNIQUE SWAP)/*//4. Update SYS1.PARMLIB(IEASYS00), adding
SYS1.PAGEL04,AfterSYS1.PAGEL02,And changing
SWAP=SYS1.PAGES01,ToSWAP=(SYS1.PAGES01,SYS1.PAGES02),5. Re-IPL the TK3UPD system, logon to TSO and use the Interactive Monitor “IM P” to verify the new page and swap packs are online.
This configuration will allow TSO swapping to occur mostly to the SWAP packs, that is, not on the same packs the demand paging system is using. Interestingly, the usual recommendation is to not use SWAP at all and let everything go to the demand paging system. Which is best for this Hercules configuration? I’ve tried them both and can tell you there is some difference, but you should be able to get the desired sub-second response either way. The way to decide which is best is, of course, to try it and see. That’s one of the main reasons people use scripting – to conduct such tests - so I’ll leave resolution of the question to those of you who care. One hint: if you want to disable swap in the above configuration, don’t try to do it by removing the “SWAP=…” in IEASYS00; do it by changing the “SWAP=…” to “SWAP=,”.
You may also find it desirable (or even necessary) to add spool space and/or general work space. The procedure is as above: update the TK3UPD.CONF file to add the packs, such as
0701 3350 dasd/js2sp1.701 ro sf=shadow/js2sp1_1.701 andthen create those packs by copying (js2sp0 to js2sp1, work02 to work06), then IPL, varying the new duplicate id packs offline, then run CLIP to change the volids.
01A1 3380 dasd/work06.1a1 ro sf=shadow/work06_1.1a1
Don't forget to update SYS1.PARMLIB(VATLST00) to identify WORK06.
WORK06,1,1,3380 ,N WORKPACK
IPL again after changing the volids and vatlst. No further action is needed: JES2 will notice the new spool pack and format it, and the system with begin allocation on the new work pack.
At this point we’re ready to bring all the terminals online. We don’t want to do this by adding all the new major nodes to ATCCON00 (so they come online at IPL) because doing so unnecessarily increasing the number of VTAM buffers required.
Of course we could simply vary them online manually, ie, issue a “V NET,ACT,ID=LCLxxx” for each of them. The downside of that idea is that there are 19 of them to vary, and it needs to be done at every IPL! It’s easier to create a proc to vary them all, using an appropriate delay between them to keep from ‘flooding’ VTAM as using ATCCON00 would. Here is JCL to catalog a proc “VARYON” to do that.
//VARYON JOB CLASS=A,MSGLEVEL=(1,1),MSGCLASS=A//*//STORE EXEC PGM=IEBUPDTE,REGION=1024K,PARM=NEW//SYSUT2 DD DSN=SYS2.PROCLIB,DISP=SHR//SYSPRINT DD SYSOUT=*//SYSIN DD DATA,DLM=$$./ ADD NAME=VARYON,LIST=ALL//VARYON PROC//VARY EXEC PGM=BSPOSCMD,PARM='V NET,ACT,ID=LCL1C0'//DELAY EXEC PGM=DELAY,PARM='2'//VARY EXEC PGM=BSPOSCMD,PARM='V NET,ACT,ID=LCL2C0'//DELAY EXEC PGM=DELAY,PARM='2'//VARY EXEC PGM=BSPOSCMD,PARM='V NET,ACT,ID=LCL3C0'//DELAY EXEC PGM=DELAY,PARM='2'//*//VARY EXEC PGM=BSPOSCMD,PARM='V NET,ACT,ID=LCLD00'//DELAY EXEC PGM=DELAY,PARM='2'//VARY EXEC PGM=BSPOSCMD,PARM='V NET,ACT,ID=LCLD10'//DELAY EXEC PGM=DELAY,PARM='2'//VARY EXEC PGM=BSPOSCMD,PARM='V NET,ACT,ID=LCLD20'//DELAY EXEC PGM=DELAY,PARM='2'//VARY EXEC PGM=BSPOSCMD,PARM='V NET,ACT,ID=LCLD30'//DELAY EXEC PGM=DELAY,PARM='2'//VARY EXEC PGM=BSPOSCMD,PARM='V NET,ACT,ID=LCLD40'//DELAY EXEC PGM=DELAY,PARM='2'//VARY EXEC PGM=BSPOSCMD,PARM='V NET,ACT,ID=LCLD50'//DELAY EXEC PGM=DELAY,PARM='2'//VARY EXEC PGM=BSPOSCMD,PARM='V NET,ACT,ID=LCLD60'//DELAY EXEC PGM=DELAY,PARM='2'//VARY EXEC PGM=BSPOSCMD,PARM='V NET,ACT,ID=LCLD70'//DELAY EXEC PGM=DELAY,PARM='2'//VARY EXEC PGM=BSPOSCMD,PARM='V NET,ACT,ID=LCLD80'//DELAY EXEC PGM=DELAY,PARM='2'//VARY EXEC PGM=BSPOSCMD,PARM='V NET,ACT,ID=LCLD90'//DELAY EXEC PGM=DELAY,PARM='2'//VARY EXEC PGM=BSPOSCMD,PARM='V NET,ACT,ID=LCLDA0'//DELAY EXEC PGM=DELAY,PARM='2'//VARY EXEC PGM=BSPOSCMD,PARM='V NET,ACT,ID=LCLDB0'//DELAY EXEC PGM=DELAY,PARM='2'//VARY EXEC PGM=BSPOSCMD,PARM='V NET,ACT,ID=LCLDC0'//DELAY EXEC PGM=DELAY,PARM='2'//VARY EXEC PGM=BSPOSCMD,PARM='V NET,ACT,ID=LCLDD0'//DELAY EXEC PGM=DELAY,PARM='2'//VARY EXEC PGM=BSPOSCMD,PARM='V NET,ACT,ID=LCLDE0'//DELAY EXEC PGM=DELAY,PARM='2'//VARY EXEC PGM=BSPOSCMD,PARM='V NET,ACT,ID=LCLDF0'//DELAY EXEC PGM=DELAY,PARM='2'./ ENDUP$$//
With this proc cataloged just type “s varyon” on the console to vary all the terminals online!
With the terminals online it’s time to try the script. That would be the script from KooKbooK recipe #7, as modified by the large list of ids, passwords, and terminals at the end of recipe #8.
Hopefully when you run this script it now works, logging on all 251 tso users on all 251 terminals[2]. If you like, consolidate the response time reports (with CAT *.RESP*.TXT >RESPONSE.XLS) and use MS Excel (or OOO Calc) to review…
FYI, As previously noted the scripts aren’t robust. They’re intended to illustrate technique, but are not “hardened” to properly handle all situations, primarily because such hardening would obscure the illustration. Most glaringly expect timeouts are not always coded, and when you’re simulating hundreds of users these timeouts happen occasionally. Resulting crashes take the form of messages that a variable is undefined. When you look at the code you see the variable in question was defined after an expected result, so it being undefined means there was a timeout. Poor “error recovery” of course, but since having a few sessions crash out from time to time doesn’t seriously impact the demonstration, I’ve judged the fix for this would be worse than the problem…
But we aren’t done yet. I’m sure you noticed that there were never more than a few dozen users logged on at once when that script ran. The reason is that the scripts completed so quickly that at about that point (25-30 logins) old scripts were finishing as fast as new scripts were being launched!
We need to revisit the script, making sure it keeps the simulated users running long enough to have them all online together for a reasonable period of time. Next week we will do that and define exactly what it means to have them “all running at once” – the usual what/when/where/why/how for each simulated user – expressed in the script. I call this defining the Workload.